Accelerate experiment velocity, without compromising rigor
Eppo is the experimentation and feature management platform that makes advanced A/B testing accessible to everyone in your organization.







.png)

.png)
.png)
.png)
.png)
.png)
.png)







Eppo powers experimentation culture
Increase experiment velocity

Make better decisions, with confidence
Activate self-serve experimentation
Warehouse-native experimentation and feature management, at scale

Advanced experiments made accessible
Warehouse-native architecture powers a world class statistical engine without becoming a black box. All raw data remains within your VPC for customer privacy. Proactive guidance, diagnostic alerts and streamlined design turn your whole team into experiment experts.
Feature flags tied to your core metrics
A single home for experiments, feature gates, rollouts, holdouts, kill switches, and no-code dynamic configuration. Lightweight SDKs for client and server prioritize speed and enable consistent assignments across environments. Route assignments to your data warehouse so you can measure impact using trusted business metrics.
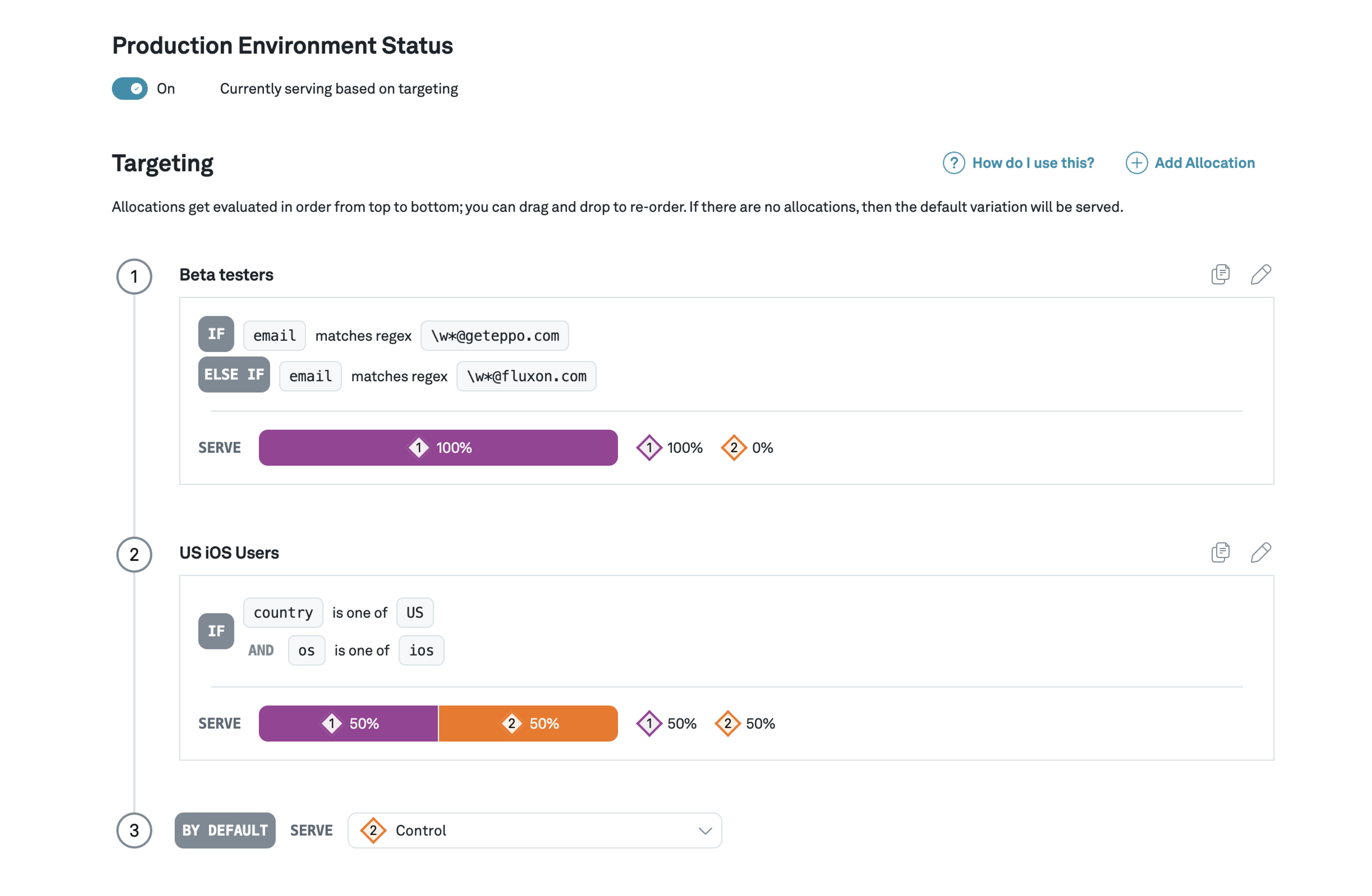
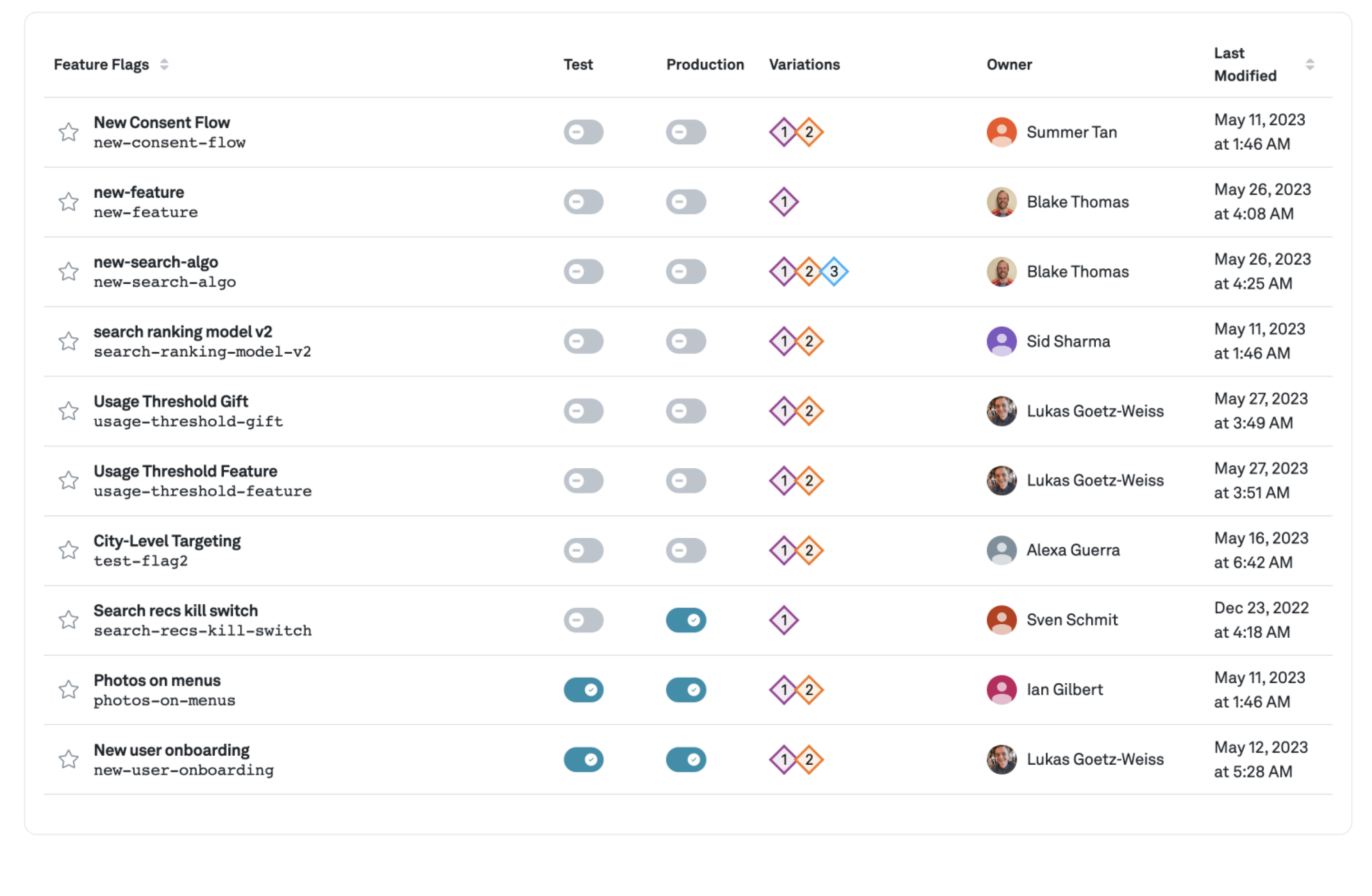
Realize the power of warehouse-native experimentation
Keep your data warehouse costs down
Eppo’s pipelines are optimized to keep your data warehouse bills down.
Avoid security and data privacy concerns
No data egressing of data, no conflicting sources, no black boxes.
Easy integration
Get trusted data in seconds—connect your data warehouse and you’re ready to go.
Complete metric governance
Data teams can own metric definitions and guardrails with version control and the semantic layer.
Loved by our customers

Eppo enables us to get insights that wouldn’t be possible in previous tools. It’s a whole new generation of A/B platform.

Head Of Data & Analytics
After switching to Eppo, our Product Managers are spending 50% less time making dashboards and debugging issues, which leaves more time to develop the features our users want.

Product Analytics Manager
Rigor, visibility, and transparency. That is Eppo. Eppo puts everyone on the same page.

Product Data Science Manager
Our team is very happy with the way we're running experiments with Eppo across front-end, back-end and Machine Learning use cases.

ML Engineering Manager




Integrations with the tools you love















